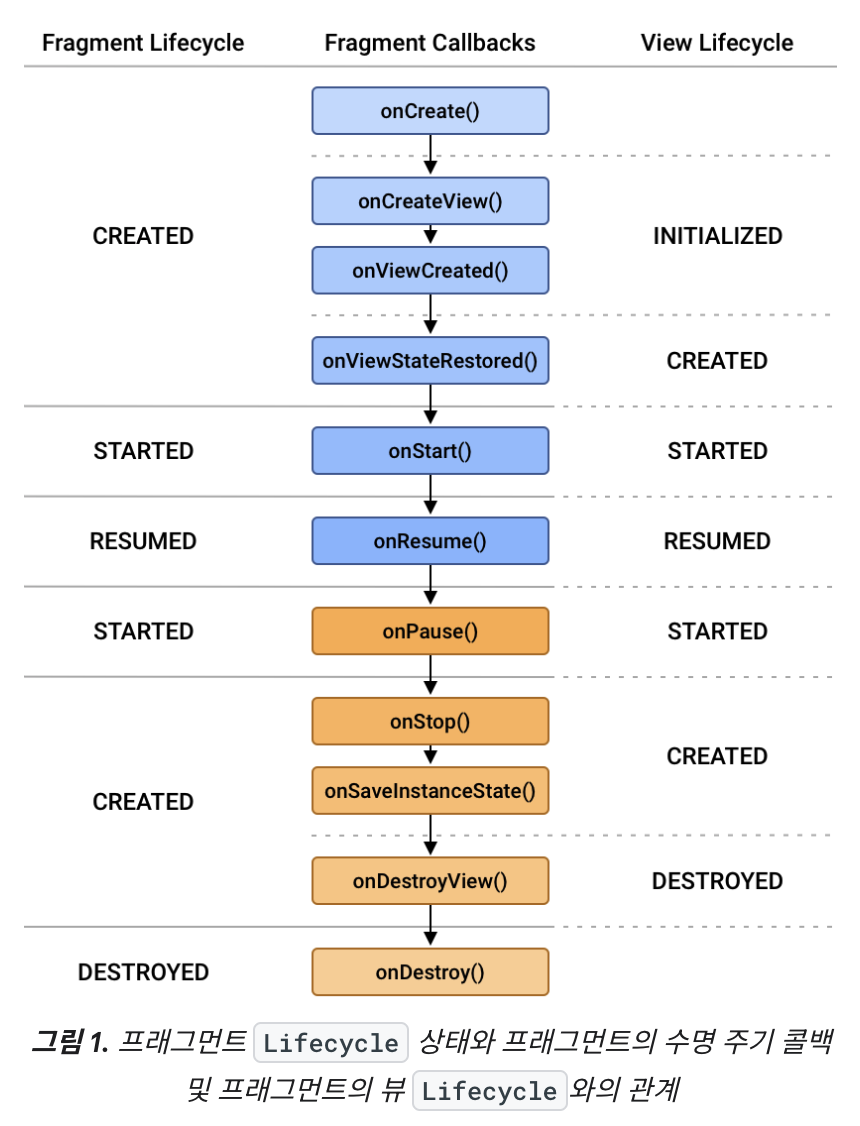
Fragment는 백스택에 있을 때 onDestroyView()가 호출되지만 Fragment 자체는 살아있는 상태다. 따라서 Fragment에서 lifecycleScope를 쓰게 되는 경우 메모리 누수가 발생할 수 있다. 이때 사용하는 게 viewLifecycleOwner.lifecycleScope이며, onViewCreated(뷰가 생성완료 되었을 때)에서 launch한다.
1 2 3 4 5 6 7 8
class TestFragment : Fragment() { override onViewCreated(...) { viewLifecycleOwner.lifecycleScope.launch { // Fragment의 lifecycle을 따르는 (Fragment의 onCreate에서 호출하는) lifecycleScope.launch와는 다르게, // Fragment의 View의 lifecycle을 따르기 때문에 "Fragment가 DESTROYED되기 전, 그리고 Fragment의 View가 DESTROYED된 후"의 메모리 누수를 방지할 수 있다. } } }
3. ViewModel의 viewModelScope
ViewModel이 clear될 때만 취소됨
Dispatchers.Main.immediate 사용
1 2 3 4 5 6 7
class TestViewModel : ViewModel() { init { viewModelScope.launch { // 해당 ViewModel의 lifecycle을 따르기 때문에 viewModel이 살아있는 동안에만(Cleared되기 전까지) 여기의 코루틴을 실행하도록 해준다. } } }
4. 앱의 ProcessLifecycleOwner.get().lifecycleScope
Application 레벨의 lifecycle을 따르며, 앱 프로세스가 종료될 때 취소된다.
onCreateView() ──► View 생성 │ onViewCreated() ──► viewLifecycleOwner.lifecycleScope 시작 │ │ │ ├─ coroutine 1 (collect openEvent) │ ├─ coroutine 2 (collect toastEvent) │ └─ coroutine 3 (collect alertEvent) │ [다른 Fragment로 이동] │ onDestroyView() ──► View 파괴 viewLifecycleOwner.lifecycleScope내 모든 코루틴이 자동 취소된다. (Fragment는 메모리(백스택)에 남아있는 상태) [뒤로가기] │ onCreateView() ──► View 다시 생성 │ onViewCreated() ──► 새로운 viewLifecycleOwner.lifecycleScope에서 새로운 코루틴들이 시작한다.
잘못 사용한 예
1 2 3 4 5 6 7 8 9 10
classMyFragment : Fragment() { overridefunonViewCreated(view: View, savedInstanceState: Bundle?) { lifecycleScope.launch { // Fragment lifecycle viewModel.events.collect { // binding.textView 접근 → onDestroyView 후에도 실행됨! binding.textView.text = "..."// 앱 크래시 가능성이 있다. } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13
onCreateView() ──► View 생성 │ ├─ lifecycleScope.launch (Fragment의 lifecycle) │ └─ collect 시작 │ onDestroyView() ──► View 파괴 (binding.textView 사라짐) │ │ (하지만 collect는 계속 실행 중인 상태) │ └─ viewModel.events.emit() 발생 └─ binding.textView.text = "..."// 앱 크래시 가능성이 있다. onDestroy() ──► 여기서야 lifecycleScope 내 코루틴들이 취소된다.
repeatOnLifecycle vs viewLifecycleOwner.repeatOnLifecycle
repeatOnLifecycle과 viewLifecycleOwner.repeatOnLifecycle도 동작 차이가 있다.
Fragment에서 사용했을 때 viewLifecycleOwner.lifecycleScope에서 launch하더라도 repeatOnLifecycle은 this.repeatOnLifecycle이기 때문에 Fragment의 View 라이프사이클이 아닌 Fragment 라이프사이클을 따르기 때문에 메모리 누수 가능성이 있다.
⚠️ 픽셀 기기에서는 컷아웃이 제대로 넘어오지 않는 것 같음. 카메라가 있는데도 컷아웃이 0으로 내려옴.
Android 9 이상을 실행하는 기기에서는 일관성, 앱 호환성을 보장하기 위해 다음과 같은 컷아웃 동작을 보장해야 한다.
단일 가장자리에 컷아웃을 최대 1개 포함할 수 있다.
기기에 컷아웃이 3개 이상 있을 수 없다.
기기 양 쪽의 긴 가장자리(세로 모드 시 좌우)에는 컷아웃이 있을 수 없다.
특수 플래그를 설정하지 않은 세로 방향에서는 상태 표시줄이 적어도 컷아웃 높이까지 확장되어야 한다.
기본적으로 전체 화면 또는 가로 방향에서는 전체 컷아웃 영역이 레터박스 처리되어야 한다.
따라서, 다음과 같은 컷아웃 유형을 지원한다.
상단 중앙: 상단 가장자리 중앙의 컷아웃
상단 비중앙: 컷아웃이 모서리에 위치하거나 중앙에서 약간 벗어날 수 있다.
하단: 하단의 컷아웃
이중: 상단의 컷아웃 1개, 하단의 컷아웃 1개
콘텐츠가 컷아웃 영역과 겹치지 않게 하려면 콘텐츠가 스테이터스 바 및 네비게이션 바와 겹치지 않게 하려면 컷아웃 영역에서 Inset을 부여하여 처리하면 해결이 가능하다.
컷아웃 영역으로 렌더링하는 경우 WindowInsets#getDisplayCutout() 함수를 사용하여 각 컷아웃의 Safe Inset Area와 Safe Area가 포함된 DisplayCutout 객체를 탐색할 수 있다. 따라서 이러한 API를 사용해 콘텐츠가 컷아웃과 겹치는지 여부를 판단하여 위치를 조정할 수 있다.
Android 15(API 35)부터는 WindowInsets#getDisplayCutout() 함수를 사용하면 된다.
컷아웃 영역은 카메라와 같은 하드웨어가 디스플레이를 가리는 경우 생긴다. 관련 예로, 폰에서 카메라 영역(컷아웃 영역) 때문에 상단 인셋을 적용했는데, 이 코드를 컷아웃 영역이 없는 태블릿에서 실행하니 컷아웃 영역이 없는데도 상단 인셋이 적용되어 버린다. 따라서 아래와 같이 컷아웃을 사용해 패딩을 설정하면 컷아웃에 따른 인셋을 설정할 수 있게 된다.
/** * Inset 생성 시 Window를 제어하기 위한 인터페이스 */ publicinterfaceWindowInsetsController{
/** * 어두운 백그라운드, 밝은 포그라운드 색상을 가진 불투명한 상태표시줄을 만듦 * @hide */ int APPEARANCE_OPAQUE_STATUS_BARS = 1; /** * 어두운 백그라운드, 밝은 포그라운드 색상을 가진 불투명한 네비게이션 바를 만듦 * @hide */ int APPEARANCE_OPAQUE_NAVIGATION_BARS = 1 << 1; /** * 상태바 레이아웃이 변경됨 없이 덜 두드러지게 상태표시줄의 아이템을 적용함 * @hide */ int APPEARANCE_LOW_PROFILE_BARS = 1 << 2; /** * 밝은 상태표시줄로 변경하여 상태바 내 아이템들의 시연성을 뚜렷하게 함 */ int APPEARANCE_LIGHT_STATUS_BARS = 1 << 3; /** * 밝은 네비게이션 바로 변경하여 상태바 내 아이템들의 시연성을 뚜렷하게 함 */ int APPEARANCE_LIGHT_NAVIGATION_BARS = 1 << 4;
... }
여기의 플래그를 보면 기존에 제공하던 아래 플래그와 전혀 다른 것을 알 수 있다.
1 2 3 4 5 6 7 8
decorView.systemUiVisibility = // 아래 SYSTEM_UI_FLAG_LAYOUT_HIDE_NAVIGATION 와 중복? View.SYSTEM_UI_FLAG_HIDE_NAVIGATION or View.SYSTEM_UI_FLAG_FULLSCREEN or // 가장 자리 스와이프 시 발동, 다만 앱에서는 인지 못함 View.SYSTEM_UI_FLAG_IMMERSIVE_STICKY or // 하단 네비게이션 바 숨기기 View.SYSTEM_UI_FLAG_LAYOUT_HIDE_NAVIGATION
여러 SDK 버전을 커버하는 WindowCompat 클래스에는 다음과 같이 분기처리가 되어 있다.
staticclassApi16Impl{ privateApi16Impl(){ // This class is not instantiable. } staticvoidsetDecorFitsSystemWindows(@NonNull Window window, finalboolean decorFitsSystemWindows){ finalint decorFitsFlags = View.SYSTEM_UI_FLAG_LAYOUT_STABLE | View.SYSTEM_UI_FLAG_LAYOUT_HIDE_NAVIGATION | View.SYSTEM_UI_FLAG_LAYOUT_FULLSCREEN; final View decorView = window.getDecorView(); finalint sysUiVis = decorView.getSystemUiVisibility(); decorView.setSystemUiVisibility(decorFitsSystemWindows ? sysUiVis & ~decorFitsFlags : sysUiVis | decorFitsFlags); } }
1 2 3 4 5 6 7 8 9 10 11
@RequiresApi(30) staticclassApi30Impl{ privateApi30Impl(){ // This class is not instantiable. } @DoNotInline staticvoidsetDecorFitsSystemWindows(@NonNull Window window, finalboolean decorFitsSystemWindows){ window.setDecorFitsSystemWindows(decorFitsSystemWindows); } }
이와 같이 Android 15(API 35) 이상에서는 Window의 Inset을 부분적으로 적용하는 경우, Window#setDecorFitsSystemWindows를 사용하면 된다.